I really banged my head on the wall on this one. I recently decided to re-architect my networking setup in proxmox to utilize bonded network configuration. I followed this writeupexactly. The problem is it didn’t work.
I would copy the example exactly, only changing the interface name, and yet every time I tried to start the networking service I would get this lovely error:
rawdevice bond0 not present
I finally found on the Debian Wiki one critical line :
First install the ifenslave package, necessary to enable bonding
For some reason the ProxMox howtos don’t speak of this – I guess because it comes installed by default. I discovered, however, that if you install ifupdown2 it removes ifenslave. I had installed ifupdown2 in the past to reload network configuration without rebooting. Aha!
I re-installed ifenslave (which removed ifupdown2 and re-installed ifupdown) and suddenly, the bond worked!
Bond not falling back to primary intrerface
I had configured my bond in active – backup mode. I wanted it to prefer the faster link, but if there was a failure in that link it wouldn’t switch back automatically (thanks to this site for showing me the command to check:
cat /proc/net/bonding/bond0
I read again in Debian bonding wiki that I needed to add this directive to the bond:
bond-primary enp2s0
Here is my complete working active-backup configuration, assigning vlan 2 to the host, and making enp2s0 (the 10gig nic) the primary, with a 1gig backup (eno1)
auto bond0
iface bond0 inet manual
slaves enp2s0 eno1
bond-primary enp2s0
bond_miimon 100
bond_mode active-backup
iface bond0.2 inet manual
auto vmbr0v2
iface vmbr0v2 inet static
address 192.168.2.2
netmask 255.255.255.0
gateway 192.168.2.1
bridge_ports bond0.2
bridge_stp off
bridge_fd 0
auto vmbr0
iface vmbr0 inet manual
bridge_ports bond0
brideg_stp off
bridge_fd 0
I recently acquired an Intel based server and plugged it into my AMD-based Proxmox cluster. I ran into an issue transferring from AMD to Intel boxes (the other direction worked fine.) After a few moments, every VM that moved from AMD to Intel would kernel panic.
Fortunately I found here that the fix is to add a few custom CPU flags to your VMs. Once I did this they could move back and forth freely (assuming they had the kvm64 CPU assigned to them – host obviously won’t work.)
qm set *VMID* --args "-cpu 'kvm64,+ssse3,+sse4.1,+sse4.2,+x2apic'"
In trying to passthrough some LSI SAS cards to a VM I kept receiving this error:
kvm: -device vfio-pci,host=0000:03:00.0,id=hostpci0,bus=ich9-pcie-port-1,addr=0x0,rombar=0: vfio 0000:03:00.0: failed to setup container for group 7: Failed to set iommu for container: Operation not permitted
I found on this post that the fix is to add a line to /etc/modprobe.d/vfio.conf with the following:
I recently began a project of segmenting my LAN into various VLANs. One issue that cropped up had me banging my head against the wall for days. I had a particular VM that would use OpenVPN to a private VPN provider. I had that same system sending things to a file share via transmission-daemon.
Pre-subnet move everything worked, but once I moved my file server to a different subnet suddenly this VM could not access it while on the VPN. Transmission would hang for some time before finally saying
transmission-daemon.service: Failed with result 'timeout'.
The problem was since my file server was on a different subnet, it was trying to route traffic to it via the default gateway, which in this case was the VPN provider. I had to add a specific route to tell the server to use my LAN network instead of the VPN network in order to restore connectivity to the file server (thanks to this site for the primer.)
I had to create a file /etc/sysconfig/network-scripts/route-eth0 and give it the following line:
192.168.2.0/24 via 192.168.1.1 dev eth0
This instructed my VM to get to the 192.168.2 network via the 192.168.1.1 gateway on eth0. Restart the network service (or reboot) and success!
I just recently got a $40 external SAS adapter for my new storage server. The plan was to create a DAS device from my old NAS chassis and have it be driven by my new storage server (new to me anyway – a Dell PowerEdge R610.) I ordered what was listed simply as “Dell SAS External Dual Ports PCI-E 6GB/S Host Bus Server Adapter 12DNW 342-0910 Consumer Electronics” from Amazon for $40 to accomplish this goal.
When I plugged everything in, to my dismay none of my disks with greater than 2TB capacity showed up. Well, they sort of showed up – they all reported capacities of exactly 2TB. I was clearly running into some sort of firmware issue.
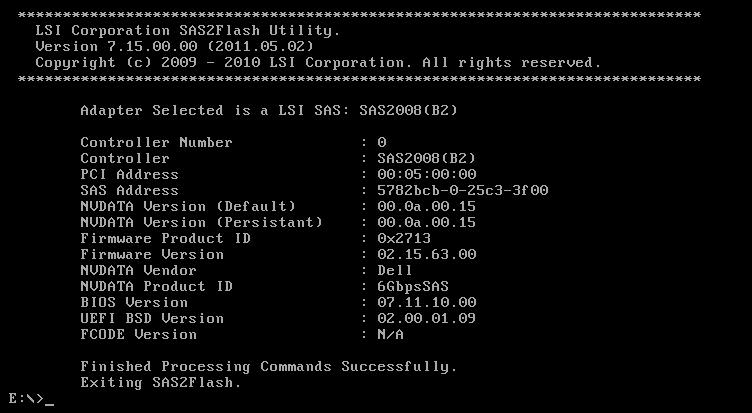
lspci revealed this card uses the LSI SAS2008 chipset, which from what I’ve read is capable of drives greater than 2TB in size. I later found the model number of my card – Dell PERC H200E – which proved to be quite vital information. After hours of digging around in unholy corners of the internet I finally arrived on this Dell Support page. It had exactly what I was hoping for:
ENHANCEMENTS: – Added support for SAS HDDs larger than 2TB
To flash this I chose to create a bootable dos ISO as per the instructions here. First, download the Windows installer, open with your archive program of choice and extract to the folder you’re going to build your ISO from. Then follow the instructions linked to above of downloading a freeDOS ISO, extracting it to the same folder you extracted the firmware to, then running the command to build your ISO (adjust as needed)
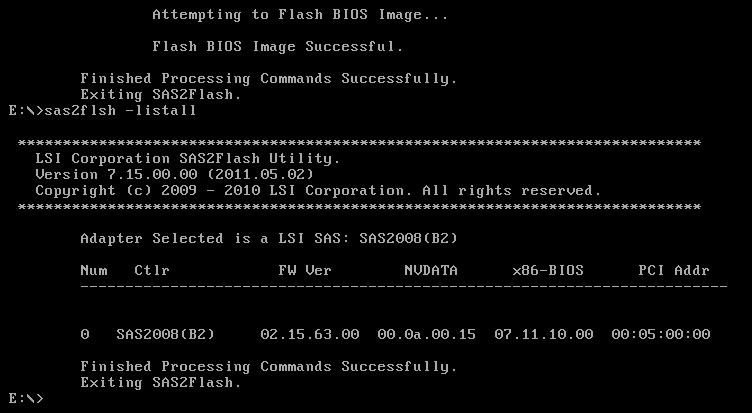
I got so far and yet tripped at the finish line. If you simply run flash.bat you’ll be greeted with a message saying no compatible adapters were found. Fortunately that’s a LIE. My savior was this writeup on how to flash certain versions of these cards to IT mode. I didn’t care about IT mode (my card is not a RAID card) but it had the information I needed. Here are the magic commands!
sas2flsh -listall
#Use the number in the first column to get the SAS Address for the card.
sas2flsh -c 0 -list
#Write down the SAS Address and continue to the next steps.
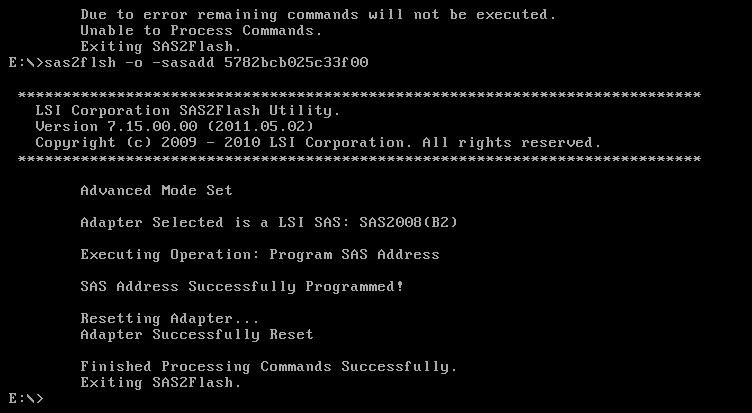
sas2flsh -o -f 6GBPSAS.FW
sas2flsh -o -sasadd 5xxxxxxxxxxxxxxx (replace this address with the one you wrote down in the first steps).
Reboot, and finally, after hours of banging my head on the wall… success!!!
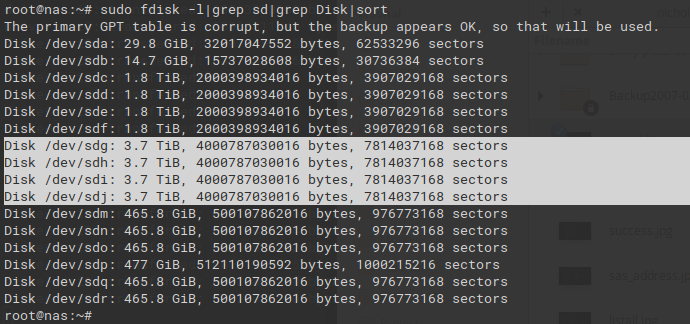
These 4 drives were only being reported as 2TB before
I had some issues with my 4tb+ drives dropping out of my zpools. I found better firmware to flash in order to fix it. It was very frustrating to flash, however. I tried following the instructions as laid out here but I was met with this lovely message:
"Cannot Flash IT Firmware over IR Firmware"..
I found this guide on how to use the megarec utility to wipe the firmware in order to flash over properly. I was able to find the megarec utility here.
I very frustratingly found I couldn’t use the megarec utility on my Dell server; megarec would simply hang
I ended up taking the card out and putting it into my desktop to run megarec commands. Comically, my desktop had a chipset that caused sas2flash not to work!! It would fail with the message
Failed to initialize PAL
Instructions per this page were to boot to EFI and run the flash utilities there, but that desktop didn’t have an EFI shell and I couldn’t get it to boot one from USB.
My final resort: an even older desktop (my Dad’s old PC, circa 2008.) It did the deed!
FINALLY
With both utilities working I was still having trouble with sas2flash erroring out on me. I finally found the wise words from fourlynx on this homelab reddit discussion on the final song and dance I had to perform to get my Dell H200 card to work with the LSI firmware I wanted
Flash to Dell 6GBPSAS.FW
I used megarec to wipe the card first before it would let me install that firmware
Erase the card
sas2flsh -o -e 7 -c 0
Flash to 6GBPSAS.FW again
sas2flsh -o -f 6GBPSAS.FW
If asked me to state a firmware, I entered 6GBPSAS.FW, waited for it to finish, then ran the sas2flsh command (flashed a total of 3 times the same firmware.)
Reboot
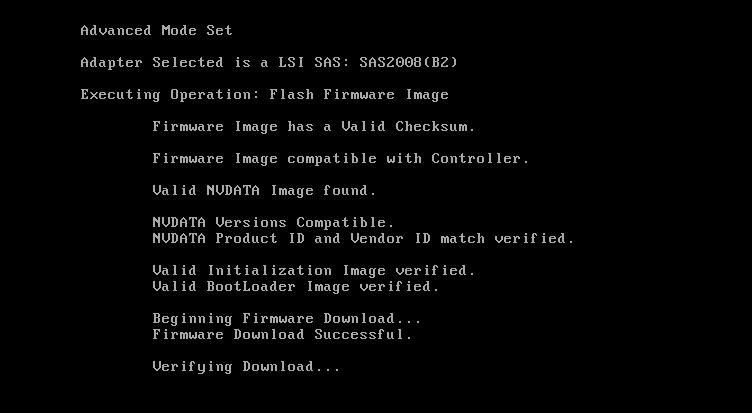
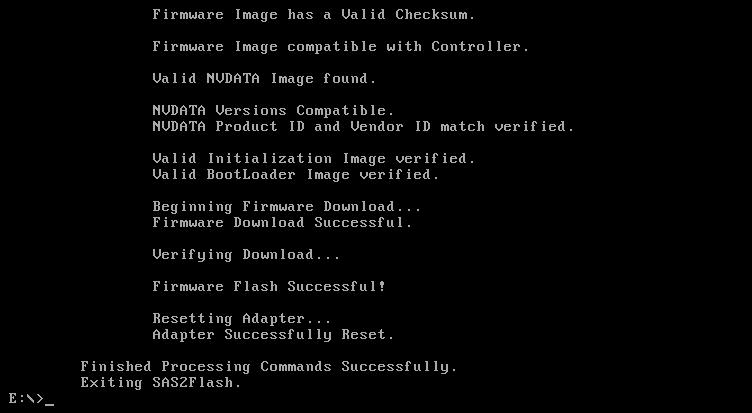
Finally flash LSI firmware
sas2flsh -o -f 2118it.bin
No need to flash BIOS (-b flag) if not going to boot from that controller. Also no need to set SAS address if it’s the only card in the server.
Words of wisdom from fourlynx:
For what concerns your case, I’d try to flash it to the Dell firmware first (any of your choice, for H200I, H200A or with the 6GBPSAS.fw). From there, clear it completely sas2flsh -o -e 7 -c 0 and flash the 6GBPSAS.fw before rebooting. You should now have better luck in crossflashing that to the LSI firmware. Note that you’ll need to use the v5 or v7 version of the flasher to do this step as newer versions will refuse to crossflash. You can then flash the bootloader for EFI (x64sas2.rom) or for BIOS (mptsas2.rom) at your leisure according to what you’re going to use, or flash both, or none if you’re not going to boot from those drives at all but instead use an USB key.
megarec -cleanflash 0 is equivalent to sas2flsh -o -e 7, btw, and the megarec -writesbr sbrempty.bin command that is often found in guides is only relevant when coming from a M1015 afaik, so not being able to use megarec is not a show stopper.
I feel I should add that, contrary to what seems the popular opinion in the various guides, these cards aren’t really easy to brick and I haven’t managed to achieve that despite all the experiments I’ve subjected them to 🙂
Update 3/8/2020
I still had issues with a drive popping out of the array so I found this page with an even better firmware for my card:
I was a bit frustrated at the lack of certain functions of ProxMox. I wanted an easy way to tag a VM and manage that tag as a group. My solution was to create HA groups for VMs with various functions. I can then manage the group and tell them to migrate storage or turn off & on.
I wrote a script to facilitate this. Right now it only covers powering on, powering off, and migrating the location of the primary disk, but more is to come.
Here’s what I have so far:
#!/bin/bash
#Proxmox HA management script
#Migrates storage, starts, or stops Proxmox HA groups based on the name and function passed to it.
#Usage: manage-HA-group.sh <start|stop|migrate> <ha-group-name> [local|remote]
#Change to the name of your local storage (for migrating from remote to local storage)
LOCAL_STORAGE_NAME="pve-1TB"
function get_vm_name() {
#Determine the name of the VMID passed to this function
VM_NAME=$(qm config "$1" | grep '^name:' | awk '{print $2}')
}
function get_group_VMIDs() {
#Get a list of VMIDs based on the name of the HA group passed to this function
group_VMIDs=$(ha-manager config | grep -B1 "$1" | grep vm: | sed 's/vm://g')
}
function group_power_state() {
#Loop through members of HA group passed to this function
for group in "$1"
do
get_group_VMIDs "$group"
for VM in $group_VMIDs
do
get_vm_name "$VM"
echo "$OPERATION $VM_NAME in HA group $group"
ha-manager set $VM --state $VM_STATE
done
done
}
function group_migrate() {
#This function migrates the VM's first disk (scsi0) to the specified location (local/remote)
#TODO String to determine all disk IDs: qm config 115 | grep '^scsi[0-9]:' | tr -d ':' | awk '{print $1}'
disk="scsi0"
#Loop through each VM in specified group name (second argument passed on CLI)
for group in "$2"
do
get_group_VMIDs "$group"
for VM in $group_VMIDs
do
#Determine the names of each VM in the HA group
get_vm_name "$VM"
#Set storage location based on argument
if [[ "$3" == "remote" ]]; then
storage="$VM_NAME"
else
storage="$LOCAL_STORAGE_NAME"
fi
#Move primary disk to desired location
echo "Migrating $VM_NAME to "$3" storage"
qm move_disk $VM $disk $storage --delete=1
done
done
}
case "$1" in
start)
VM_STATE="started"
OPERATION="Starting"
group_power_state "$2"
;;
stop)
VM_STATE="stopped"
OPERATION="Stopping"
group_power_state "$2"
;;
migrate)
case "$3" in
local|remote)
group_migrate "$@"
;;
*)
echo "Usage: manage-HA-group.sh migrate <ha-group-name> <local|remote>"
;;
esac
;;
*)
echo "Usage: manage-HA-group.sh <start|stop|migrate> <ha-group-name> [local|remote]"
exit 1
;;
esac
I recently acquired a Dell PowerEdge R610 and had a hard time getting its iDRAC to work properly on my ElementaryOS setup (Ubuntu 18.04 derivative.) I had two problems: Connection failed error and keyboard not working.
The post explains the problem is with the security settings of Java 8+ preventing the connection. I didn’t know where my security file was so I first ran a quick find command to find it:
sudo find / -name java.security
In my case it was located in /etc/java-11-openjdk/security/java.security
The last step was to remove RC4 from the list of blacklisted ciphers, as this is the cause of the problem.
Update 2022-04-13 I recently had an issue where the keyboard didn’t work despite having Java 8. I fixed it by going to Tools and checking “Pass all keystrokes to server” within the jvm window.
My system was defaulting to using JRE 11, which apparently causes the keyboard to not function at all. I found on this reddit post that you really need an older version of Java. To do so on Ubuntu 18.04 you need to install it along with the icedtea plugin and run update-alternatives
sudo apt install openjdk-8-jre icedtea-8-plugin
Edit /etc/java-8-openjdk/security/java.security and remove the restriction on the RC4 algorhythm. Then configure the system to run java 8:
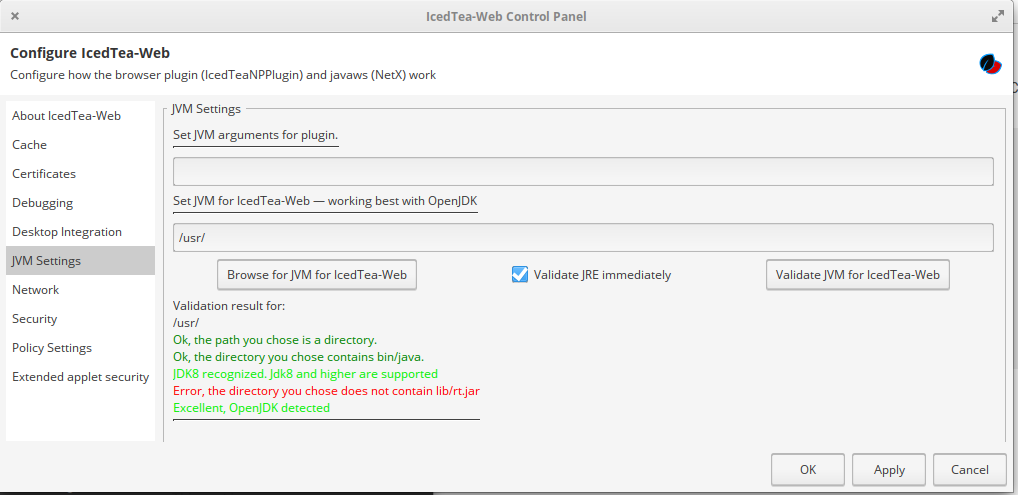
Lastly, configure the icedtea plugin to run Java 8 instead of 11, because for some reason this plugin ignores the system java settings. Launch the IcedTea Web Control panel (find it in your system menu) and then Navigate to JVM settings. Enter /usr/ in the section “Set JVM for IcedTea-Web – working best with OpenJDK” section. Then hit Apply / OK
Phew. FINALLY you should be able to use iDRAC 6 on your modern Ubuntu system.