After a few very frustrating experiences I’ve decided I want to migrate away from Sophos UTM for my home firewall. I enjoy Sophos’ features but do not enjoy the sporadic issues it’s been giving me.
My colleagues all rave about pfSense and how awesome it is so I thought I would give it a try. I have a completely virtualized setup using Citrix Xenserver 6.5 which has prevented me from trying pfSense in the past. The latest release, version 2.2.2, is based on FreeBSD 10.1, which includes native Xen device support. Now we’re talking.
Installation was quick and painless. After some configuration, the basic internet connection function was working swimmingly. As soon as I tried to forward some ports from my WAN interface to hosts on my network, though, things did not go well at all. I began to doubt my ability to configure basic NAT.
It looks simple enough – go to Firewall / NAT, specify the necessary source and destination IPs and Ports, and click apply. Firewall rules were added automatically. Except it didn’t work. I enabled logging on everything and there were no dropped packets to be found, but they were clearly being dropped. I thought it might be something weird with Sophos being upstream so I built my own private VM network but the issue was the same. NAT simply didn’t work. Silently dropped packets. I am not a fan of them.
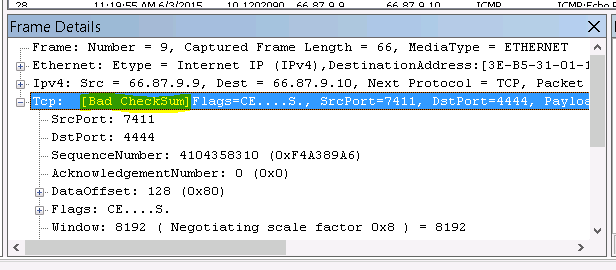
I was about to give up on pfSense but something told me it had to be a problem with my virtualization setup. I ran a packet capture via Diagnostics / Packet capture and after much sifting I found this gem:
 All of my packets sent to the WAN interface returned [Bad CheckSum] that I was only able to discover via packet capture – they weren’t in the logs anywhere.
All of my packets sent to the WAN interface returned [Bad CheckSum] that I was only able to discover via packet capture – they weren’t in the logs anywhere.
Armed with this information I stumbled on this forum post and discovered I am not alone in this. There apparently is a bug with FreeBSD 10.1 and the virtIO network drivers used by Xen, KVM, and others that causes it to miscalculate checksums, resulting in either dropped or very slow packets (I experienced both.)
The solution is to disable tx checksum offloading on both the PFsense side and the hypervisor side. In pfSense this is done by going to System / Advanced / Networking and checking “Disable hardware checksum offload”
To accomplish this on the xenserver side, follow tdslot’s instructions from the forum post linked above, replacing vm-name-label with the name of your pfSense VM:
Find your PFsense VM network VIF UUID’s:
Then modify those VIF UUID’s captured above with the following settings (discovered thanks to this post)
- other-config:ethtool-gso=”off”
- other-config:ethtool-ufo=”off”
- other-config:ethtool-tso=”off”
- other-config:ethtool-sg=”off”
- other-config:ethtool-tx=”off”
- other-config:ethtool-rx=”off”
xe vif-param-set uuid=08fa59ac-14e5-f087-39bc-5cc2888cd5f8 other-config:ethtool-tx="off"
xe vif-param-set uuid=799fa8f4-561d-1b66-4359-18000c1c179f other-config:ethtool-tx="off"
Lastly, shutdown the VM and start it again (not reboot, must be a full shutdown and power on.)
It worked! NAT worked as expected and a little bit of my sanity was restored. I can now make the switch to pfSense.