It has recently come to my attention that WordPress has a serious design flaw: it’s trivially easy to execute a denial of service attack against it in its default state. One simply has to hold down F5 to cause the site to slow to a crawl and in many cases crash entirely.
The reason behind this is that every single page request turns into the server parsing PHP code and executing a database call. Holding down F5 initiates hundreds of page view requests, which turn into hundreds of PHP code execution threads (each taking up CPU and memory) and hundreds of database calls. The server becomes quickly overwhelmed and runs out of resources.
The solution to this problem (on CentOS 7 at least) is a combination of php-fpm, zendopcache, APC, varnish and W3 Total Cache. It’s definitely more complicated but it eliminates this problem and massively increases site load times and general responsiveness.
Repositories
To install the required addons we will need to have the epel repository enabled:
yum -y install epel-release
zend-opcache
This caches PHP opcode to greatly speed up PHP code execution. It’s included in later versions of PHP but alas CentOS 7 is stuck on PHP 5.4, which does not include such caching. You have to install it manually. Thanks to this site for the information.
sudo yum -y install php-pecl-zendopcache
apc
This is another kind of of cache – this time for database operations.
sudo yum -y install php-pecl-apcu php-devel gcc sudo pecl install apc #accept defaults when prompted
php-fpm
php-fpm is a different way to serve up PHP code. Instead of apache running a module to interpret php code, it will send all php requests to a separate PHP server, optimized for speed. That php server will interpret the code and return the results to your browser.
sudo yum -y install php-fpm sudo systemctl enable php-fpm
Modify your apache config to forward all php requests to php-fpm. Be sure to modify this to match your site URL setup:
sudo sh -c "echo ' <LocationMatch \"^/(.*\.php(/.*)?)$\"> ProxyPass fcgi://127.0.0.1:9000/var/www/html/\$1 </LocationMatch>' >> /etc/httpd/conf/httpd.conf"
Varnish
Varnish is a reverse proxy server optimized for caching pages. It sits between your visitors and your webserver and caches whatever it can to increase responsiveness and speed. This site pointed me in the right direction for configuring Varnish in CentOS 7.
sudo yum -y install varnish sudo systemctl enable varnish
Change apache to listen on port 8080 instead of port 80:
sudo sed -i /etc/httpd/conf/httpd.conf -e 's/Listen 80/&80/'
Change varnish to listen on port 80 instead of port 6081:
sudo sed -i /etc/varnish/varnish.params -e 's/VARNISH_LISTEN_PORT=6081/VARNISH_LISTEN_PORT=80/g'
Now we need to configure Varnish to properly cache wordpress sites. I found the configuration from this site to be the most helpful. I normally include code blocks to copy and paste but the configuration file is pretty big.
Instead, click here for the configuration code, then copy the whole page and paste it into your terminal.
Update 12/28/2016: I’ve updated the varnish configuration code slightly to allow the “purge all caches” button of W3 Total cache to work. Thanks to this site for pointing me in the right direction and this thread for getting me there.
After varnish has been configured, restart your new PHP / caching stack:
sudo systemctl restart httpd varnish php-fpm
Logging
Update: added this section on 11/4/2016
By default varnish does not log its traffic. This means that your apache log will only log things varnish does not cache. We have to configure varnish to log traffic so you don’t lose insight into who is visiting your site.
Update 2/14/2017: I’ve discovered a better way to do this. The old way is still included below, but you really should use this other way.
New way:
CentOS ships with some systemd scripts for you. You can use them out of the box by simply issuing
systemctl start varnishncsa systemctl enable varnishncsa
If you are behind a reverse proxy then you will want to tweak the varnishncsa output a bit to reflect x-forwarded-for header values (thanks to this github discussion for the guidance.) Accomplish this by appending a modified log output format string to /lib/systemd/system/varnishncsa.service:
sudo sed -i /lib/systemd/system/varnishncsa.service -e "s/ExecStart.*/& -F \'%%{X-Forwarded-For}i %%l %%u %%t \"%%r\" %%s %%b \"%%{Referer}i\" \"%%{User-agent}i\"\' /g"
Lastly, reload systemd configuration, enable, and start the varnishncsa service:
sudo systemctl daemon-reload sudo systemctl enable varnishncsa sudo systemctl start varnishncsa
Old way:
First, enable rc.local
sudo chmod +x /etc/rc.local sudo systemctl enable rc-local #you can ignore errors here
Next, add this entry to the rc.local file:
sudo sh -c 'echo "varnishncsa -a -w /var/log/varnish/access.log -D -P /var/run/varnishncsa.pid" >> /etc/rc.local'
If your varnish server is behind a reverse proxy (like a web application firewall) then modify the above code slightly (thanks to this site for the information on how to do so)
sudo sh -c "echo varnishncsa -a -F \'%{X-Forwarded-For}i %l %u %t \"%r\" %s %b \"%{Referer}i\" \"%{User-agent}i\"\' -w /var/log/varnish/access.log -D -P /var/run/varnishncsa.pid >> /etc/rc.local"
W3 Total Cache
The improvements above will greatly increase your speed and eliminate the F5 denial of service issue. The last bit to make it even sweeter is to install the W3 Total Cache wordpress plugin. Thanks to this site for the information that pointed me in the right direction.
There are a ton of options in W3 Total cache that are beyond the scope of this tutorial. For our purposes we will enable the following options in the General Settings tab of the plugin:
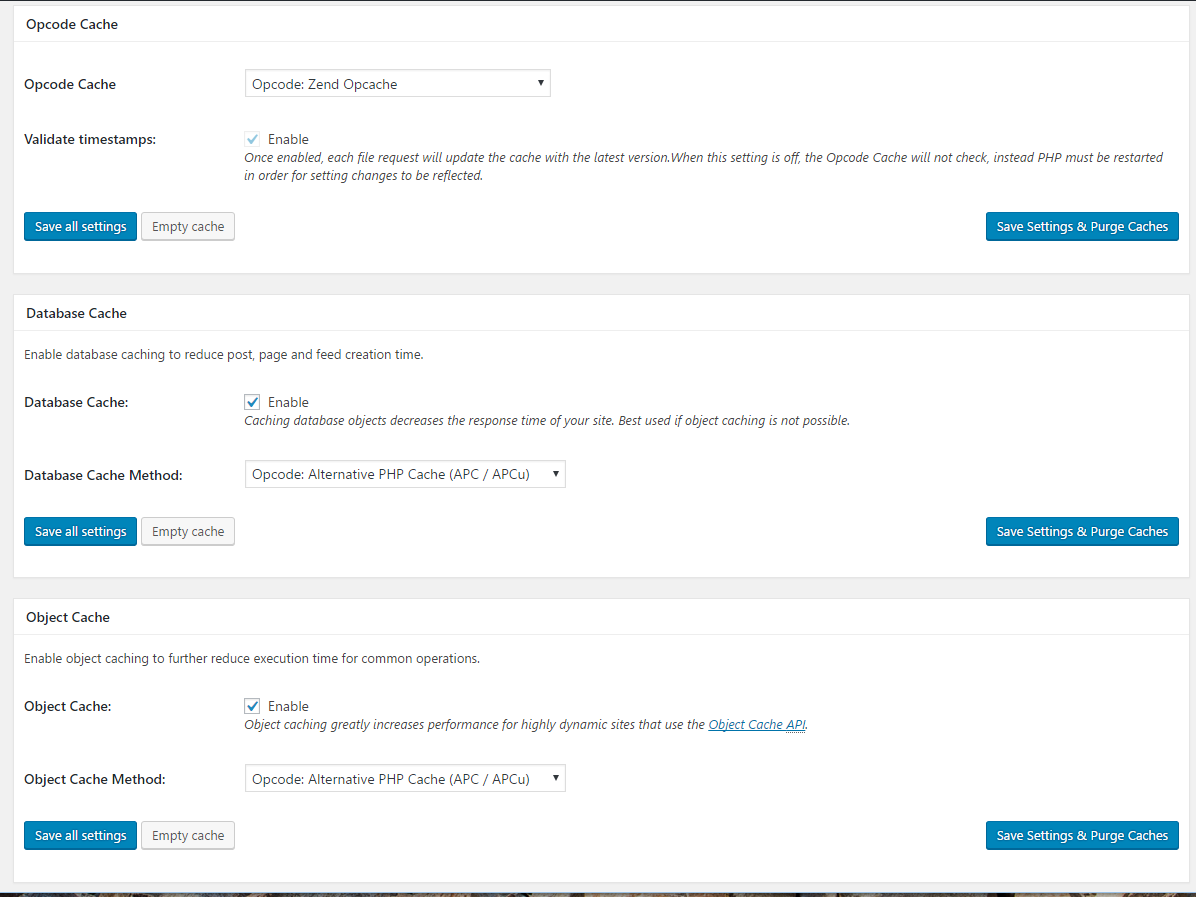
Opcode cache: Opcode:Zend Opcache
Database cache: Check enable, select Opcode: Alternative PHP Cache (APC / APCu)
Object cache: Check enable, select Opcode: Alternative PHP Cache (APC / APCu)
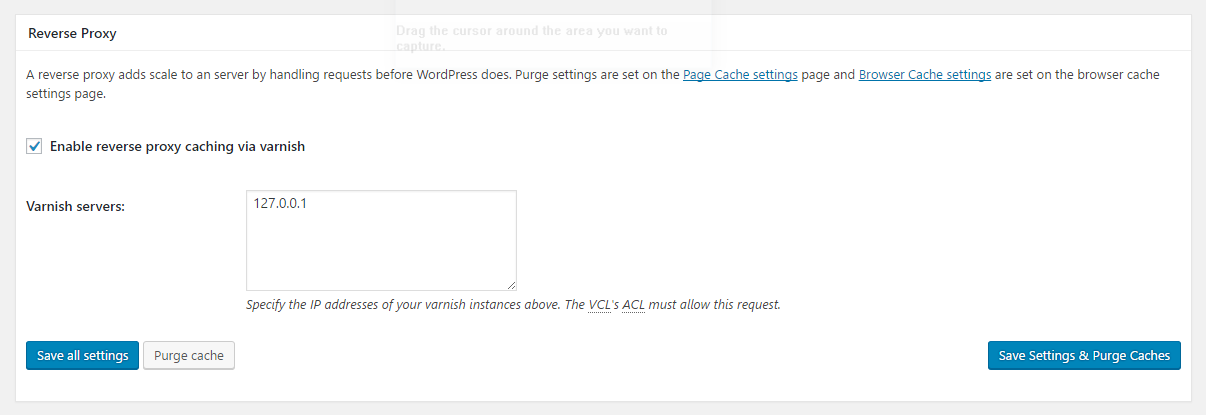
Reverse Proxy: Check “Enable reverse proxy caching via varnish”
Specify 127.0.0.1 in the varnish servers box. Click save all settings.
Full speed ahead
With all of these pieces into place your site is definitely more complicated, but it is also much faster to load. Enjoy.
Troubleshooting
If you go through all these steps only to see this very non-descriptive message:
File not found
it means you have PHP forwarding to the wrong directory. Modify the LocationMatch section you inserted at the bottom of /etc/httpd/conf/httpd.conf earlier to ensure the correct directory structure is passed for php files.